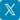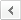|
지난 3월 16일에 경기북과학고등학교에서 2015년 1차 방과 후 특기적성이 시작되었다. 이 중 ‘로봇공학연구’ 강좌에서는 ‘가감속 제어’, ‘효율적인 라인트레이서’, ‘센서 필터링’, ‘인공지능 라인트레이서’, ‘로보암’, ‘옴니휠’ 등 다양한 주제의 로봇 연구를 진행하였다. 그 중 내가 진행하였던 ‘인공지능 라인 트레이서’에 대해 소개하고자 한다.
Q-Learning이란?
인공지능이란 인간의 지능을 모방하여 사람의 학습, 지각, 추론, 자기계발 등을 컴퓨터가 할 수 있도록 하는 방법을 의미한다. 그 중에서 Q-Learning 알고리즘은 전체적인 맵의 형태를 기억하는 것이 아니라 현재 상태만을 사용하여 수행할 행동을 선택하기 때문에 계산 시간 및 메모리 요구가 적다. 또한 Q-Learning 알고리즘은 로봇이 자신의 상태를 인지하고, 어떠한 행동을 수행한 후 그 결과에 따라 긍정적인, 또는 부정적인 보상을 받는다. 예를 들어 라인 트레이싱을 하면서 로봇이 라인 밖으로 이탈하였을 때 로봇이 라인 안쪽으로 돌아오는 행동을 했다면 긍정적인 보상을 받아 앞으로 그 행동을 더 자주 수행하고, 오히려 라인으로부터 멀어지는 행동을 했다면 부정적인 보상을 받아 앞으로 그 행동을 수행하지 않게 된다. ROBOTC 기반의 EV3 환경에서는 사용할 수 있는 메모리 공간이 크지 않기 때문에 이러한 Q-Learning 알고리즘을 사용하기로 하였다.
| |
 |
|
| ▲ 주행하고자 하는 맵의 형태 |
인터넷을 통해 인공지능과 Q-Learning 알고리즘에 대한 기본적인 지식을 알아본 뒤에 Q-Learning 알고리즘을 적용시킨 로봇 주행 영상을 YouTube에서 찾아보았다. 기어가는 로봇, 지팡이를 이용하여 앞으로 나아가는 로봇, 그리고 라인 트레이싱 로봇의 주행 영상도 볼 수 있었다. Q-Learning 알고리즘을 사용한 로봇들은 모두 처음에는 주어진 목표를 해결하지 못하지만, 시간이 갈수록 잘 해결해 내는 모습을 보여주었다. 하지만 동영상을 본 이후에도 Q-Learning 알고리즘을 적용시킨 라인트레이서를 어떻게 만들고 어떻게 프로그래밍 해야 할지 감이 잡히지 않았다. 이렇게 이해가 어느 정도 된 것 같으면서도 아직 잘 정리가 되지 않는 상태로 며칠을 보냈고 아무런 진전이 없다는 것을 느껴 과감하게 로봇을 만들기 시작했다.
로봇 구조 설계
먼저 로봇의 구조를 설계하였다. 처음에는 많이 사용되는 원 센서 라인 트레이서의 구조를 떠올리고 빛 센서를 하나만 사용하는 방법을 떠올렸다. 하지만 센서를 하나만 사용하는 구조는 큰 문제가 있다는 것을 알 수 있었다. 센서 값의 변화만으로는 로봇이 라인의 오른쪽으로 빠져나갔는지 왼쪽으로 빠져나갔는지 판단할 수 없다. 즉 로봇의 현재 상태를 파악하는 데 어려움이 있었다. 또한 검은 선의 왼쪽 경계를 따라갈 때와 오른쪽 경계를 따라갈 때에 학습되어야 할 내용이 다르고, 학습이 되지 않은 로봇이 한쪽 경계를 따라갈 것이라고 기대하기 어렵기 때문에 센서를 한 개 사용하는 방법은 배제해야 했다.
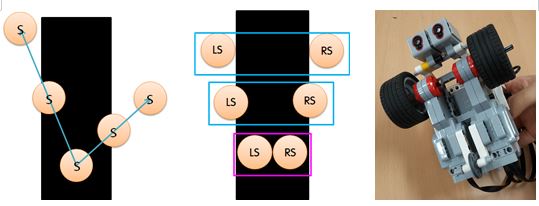
그 후, 빛 센서를 두 개 사용하는 방법을 고려하였다. 이 경우에는 로봇이 선에서 벗어날 때 벗어나는 방향을 알 수 있으므로 현재 로봇의 상태를 정확히 파악할 수 있고, 이는 Q-Learning 알고리즘을 적용할 수 있다는 것을 의미한다. 두 개의 빛 센서를 배치하는 방법으로는 두 센서 모두 라인 바깥에 놓여 있는 배치, 두 경계에 걸쳐져 있는 배치, 그리고 검은 선 안에 두 개의 빛 센서가 놓여 있는 배치를 생각할 수 있었다. 그 중에서 두 개의 빛 센서가 모두 라인 바깥에 놓여 있는 배치는 현재 잘 주행하고 있는 상황인지, 아니면 라인을 완전히 이탈한 상황인지 구분할 수 없기 때문에 다른 배치를 사용하였다. 나머지 두 배치는 모두 사용할 수 있었지만, 학습에 사용하기 위한 빛 센서 값의 폭을 보다 넓히고 경계선에서 발생하는 빛 센서 값의 오차를 줄이기 위해 두 빛 센서가 모두 검은 선 안에 놓여있는 배치를 사용하여 로봇을 완성했다.
| |
 |
|
| ▲ 빛 센서 하나를 사용할 때 발생하는 문제점(좌)과 두 빛 센서의 배치 가능성(중), Q-Learning Line Tracing을 할 수 있도록 제작한 로봇의 모습(우) |
소프트웨어 설계
소프트웨어 설계는 크게 세 단계로 나누어진다. 첫 번째는 0부터 100까지의 값을 가질 수 있는 빛 센서 값과 모터 값을 몇 개의 구간으로 나누는 모델링, 두 번째는 현재 상태와 보상 값을 고려하여 수행할 행동을 선택하는 행동 선택, 세 번째는 행동에 따라 긍정적이거나 부정적인 보상을 부여하는 보상 체계이다.
1. 모델링
로봇이 학습을 하고 그 결과를 이용하여 학습을 계속 해 나가기 위해서는 학습 결과를 저장할 수 있어야 한다. 또한 Q-Learning 알고리즘에서는 행동을 수행하기 전의 상태와 특정 행동을 수행한 후의 상태만으로 학습을 진행한다. 따라서 행동을 수행하기 전인 현재의 상태가 주어질 때, 해당 상태에서 수행할 수 있는 최적의 행동을 선택할 수 있어야 한다. 이는 한 가지 상태에서 각각의 행동을 했을 때 얻었던 보상 값을 저장할 수 있어야 한다는 것을 의미한다. 아래 표에서 보상 값이 클수록 긍정적인 보상을 많이 받았음을 의미하고, 보상 값이 가장 큰 행동이 해당 상태에서의 최적의 행동이 된다.
| |
 |
|
| ▲ 현재 상태에서 수행할 수 있는 행동의 보상 값 |
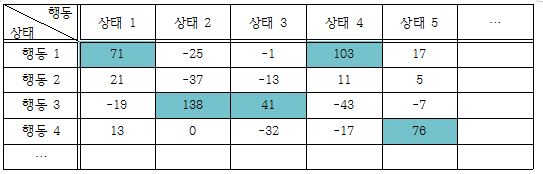
로봇이 학습을 할 때는 다양한 상태가 발생하므로, 각각의 상태에 따른 최적의 행동을 선택할 수 있어야 한다. 즉, 가질 수 있는 모든 상태에 대하여 가질 수 있는 모든 행동의 보상 값을 저장할 수 있어야 한다.
| |
 |
|
| ▲ 모든 상태에 대한 모든 행동의 보상값 |
이러한 방법으로 0부터 100까지의 모든 빛 센서 값에 대한 모든 모터 값을 저장하기 위해서는 빛 센서를 2개, 모터를 2개 사용하므로 101⁴개의 배열 공간이 필요하게 된다. 하지만 이렇게 큰 배열을 사용하게 되면 많은 메모리 공간이 필요하고, 학습 시간이 오래 걸리는 문제가 발생한다. 따라서 빛 센서 값과 모터 값을 몇 개의 구간으로 나누어주는 모델링 과정이 필요하다.
실제 센서의 값은 0부터 100까지 나타나지 않고, 모터 값을 사용할 때에도 0부터 100까지의 모든 구간을 사용하지 않으므로 센서 값과 모터 값의 범위를 한정시켜 주었다. 센서 값의 범위를 정할 때에는 검은 선 위와 흰 영역 위에서 센서 값을 측정한 후 해당 범위 내에서 정하였고, 모터 값의 범위는 경험적으로 최댓값과 최솟값을 설정해 주었다. 필자는 센서 값을 16~45, 모터 값은 14~48로 한정해 주었다.
또한 센서와 모터 값이 미세하게 차이 나는 경우는 큰 의미를 갖지 못하므로 몇 개의 센서 값 또는 몇 개의 모터 값을 묶은 구간의 개수를 정해 주었다. 필자는 센서 값을 6개의 구간, 모터 값을 5개의 구간으로 나누었다. 그 결과 101⁴개의 배열 공간을 간소화시켜 6²*5² = 900개의 배열 공간으로 축소시킬 수 있었다. 이러한 배열 공간의 축소로 인해 저장하는 데 필요한 공간이 감소할 뿐 아니라 학습 시간 또한 단축된다. 하지만 여러 센서 값 또는 모터 값을 묶어서 처리하기 때문에 미세한 변화는 잘 판단하지 못하게 되어 정교함이 떨어지는 단점도 있다.
| |
 |
|
| ▲ 센서 구간에 따른 실제 센서 값 |
| |
 |
|
| ▲ 모터 구간에 따른 실제 모터 값 |
이렇게 모델링 된 센서 값과 모터 값을 바탕으로 각각의 상태에 따른 최적 행동을 구하기 위한 배열을 설정하고자 한다. 이 배열의 이름을 memory라고 정하면, 배열은 memory[왼쪽 센서의 구간 수][오른쪽 센서의 구간 수][왼쪽 모터의 구간 수][오른쪽 모터의 구간 수]와 같이 설정할 수 있다. 즉, 필자의 경우에는 memory[6][6][5][5]와 같이 설정할 수 있다. 아래 표는 보다 알아보기 쉽도록 4차원 배열을 2차원으로 표현하였다. 아래 표에서 센서 값 (a,b)는 왼쪽 센서가 a구간 오른쪽 센서는 b구간에 속함을 의미하며, 모터 값 (c,d)는 왼쪽 모터가 c구간 오른쪽 모터는 d구간에 속함을 의미한다.
| |
 |
|
| ▲ 4차원 배열의 형태 |
하지만 ROBOTC에서 4차원 배열을 지원하지 않아 2차원 배열을 사용하여 정보를 저장해야 한다. 이를 2차원 배열로 나타내기 위해서는 센서 값의 쌍과 모터 값의 쌍을 풀어 하나의 정수로 나타내는 변환 과정을 거쳐야 한다. 이에 따라 배열의 공간은 memory[(센서의 구간 수)²][(모터의 구간 수)²]과 같이 설정해야 한다. 즉, 필자는 memory[36][25]로 설정하였다. 센서의 변환 값은 (센서 값의 구간 수)진법을 10진법으로 변환하는 과정을 통해 구할 수 있다. 마찬가지로 모터의 변환 값은 (모터 값의 구간 수)진법을 10진법으로 변환하는 과정을 통해 구할 수 있다. 예를 들어 필자는 왼쪽에 있는 센서 또는 모터를 높은 자리에 두었다. 이 때, 센서 값의 구간 수가 6이므로 (2,3)을 변환하면 2*6¹ + 3*1 = 15가 된다. 또한 모터 값의 구간 수가 5이므로 (2,1)을 변환하면 2*5¹ + 1*1 = 11이 된다. 학습이 진행되지 않은 초기 상태에는 배열에 들어있는 보상 값을 모두 같은 값으로 초기화 시켜 주어야 한다. 필자는 보상 값을 모두 50으로 초기화 시켜 주었다.
| |
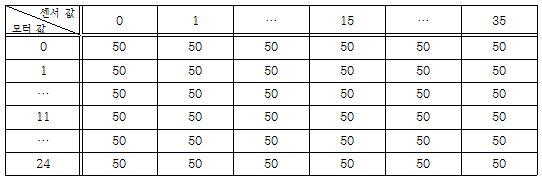 |
|
| ▲ 초기화 한 배열의 상태 |
2. 행동 선택
로봇이 Q-Learning 알고리즘을 이용하여 학습을 하므로 로봇은 행동을 수행하기 전의 상태를 파악할 수 있어야 하고, 그 상태에서 수행할 행동을 선택하여 행동하고, 행동을 수행한 후의 상태를 파악할 수 있어야 한다.
빛 센서 값을 측정하고, 측정한 빛 센서 값이 속해 있는 범위를 선택하여 로봇의 상태를 파악할 수 있다. 예를 들어 필자가 측정한 왼쪽 센서 값이 34, 오른쪽 센서 값이 44라면 왼쪽 센서 값은 3번째 구간, 오른쪽 센서 값은 5번째 구간에 해당하므로 센서 값 구간의 쌍을 (3,5)와 같이 나타낼 수 있고, 센서의 변환 값은 23에 해당한다. 이 때, 센서 값의 범위를 검은 선 위에 있을 때 센서 값과 흰 영역 위에 있을 때 센서 값의 사이에서 정하였기 때문에 최솟값보다 작은 값 또는 최댓값보다 큰 값이 나타날 수 있다. 이렇게 최솟값보다 작은 값은 최솟값으로, 최댓값보다 큰 값은 최댓값으로 취급하였다. 이 과정을 적용하여 필자가 설정한 센서 값의 범위를 다시 나타내면 아래 표와 같다.
| |
 |
|
| ▲ 센서 구간에 따른 실제 센서 값 |
이렇게 변환한 센서 값에서 수행할 행동을 선택한다. 행동을 수행하기 전의 상태를 파악한 뒤, 해당 상태에서 가장 보상 값이 높은 행동만을 선택하여 행동하면 학습이 완료될 것이라고 생각할 수 있다. 하지만 이렇게 보상 값이 가장 높은 행동만을 선택한다면 학습 초기에 긍정적인 보상을 받은 행동만 계속해서 수행하고, 다른 행동을 수행하지 않게 되어 다양한 학습의 기회를 크게 감소시킨다. 따라서 가장 보상 값이 높은 5개의 행동을 선택한 후 한 가지 행동을 선택하여 수행하게 하였다.
보상 값이 가장 큰 5개의 행동을 선택하기 위해서는 삽입 정렬 알고리즘을 이용하였다. 이미 지금까지 가장 큰 5개의 보상 값이 배열에 정렬되어 있다고 하고, 새로운 값이 추가될 경우에는 정렬되어 있는 값 중에서 가장 작은 값과 새로운 값을 비교한 후 추가되는 값이 더 크다면 배열에 넣기 위한 작업을 수행하였다. 배열에 넣어줄 때에는 추가되는 값보다 작은 값을 한 칸씩 뒤로 미루고 빈자리에 새롭게 추가되는 값을 넣어주었다. 이렇게 모든 행동에 대한 보상 값을 추가하면 보상 값이 가장 큰 5개의 행동을 선택할 수 있다. 이 과정을 수행하기 위해서는 배열의 초깃값이 추가될 수 있는 최솟값보다 작아야 한다. 필자는 ROBOTC에서 int형의 최솟값인 –32768로 배열을 초기화 해 주었다. 하지만 가장 큰 보상 값 5개만을 저장해 놓는다면 실제로 수행하기 위한 행동 정보가 없어 행동을 할 수 없다. 따라서 보상 값을 정렬하면서 해당 보상 값에 해당하는 모터 값을 다른 배열에 저장하여 행동 정보를 사용할 수 있도록 하였다.
| |
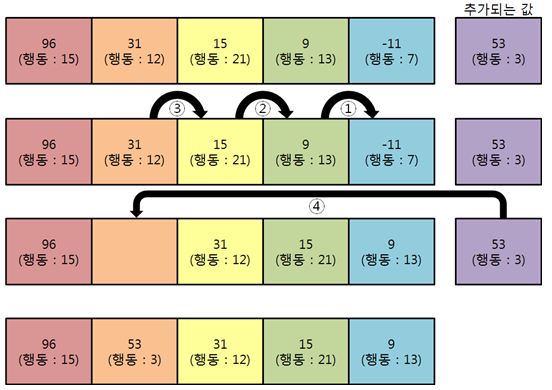 |
|
| ▲ 보상 값이 가장 큰 5개의 행동을 선택하는 과정 |
아래에서 더 자세하게 설명하겠지만, 선택된 행동들 중에서 실제로 수행할 행동 하나를 고르기 위해 각각의 행동의 보상 값으로 적용 확률을 설정하였다. 이 때, 적용 확률은 보상 값이 클수록 높여 주어야 한다. 이러한 방법은 학습이 많이 진행되지 않은 초기에는 적용 확률이 낮아 다양한 행동을 시도할 수 있고, 학습이 완료되었을 때는 적용 확률이 매우 높아져 학습된 행동을 수행할 수 있도록 한다.
적용 확률을 설정할 때는 , , 등 보상 값이 커질수록 증가하는 값을 모두 사용할 수 있을 것이다. 필자는 이 중에서 보상 값이 클수록 적용 확률을 더 크게 증가시키기 위해 꼴의 식을 사용했고, 실제로 적용시킨 식은 이다. 이 식에서 (상수1)은 학습이 많이 진행되지 않았을 때의 초기 확률을 설정해 주는 역할을 하고, (상수2)는 학습이 진행되면서 적용 확률을 증가시킬 정도를 설정해 주는 역할을 한다. 그리고 이 확률에 해당할 때, 해당 행동을 선택한다. 예를 들어 가장 높은 보상 값을 선택한 결과가 96, 53, 31, 15, 9일 경우, 행동 1을 선택할 확률은 0.78(78%)이 된다. 이 때, 행동 1을 선택했다면 행동 1을 수행한다. 행동 1을 선택하지 않았다면 행동 2를 선택할 확률은 0.31(31%)가 된다. 이 때, 행동 2를 선택했다면 행동 2를 수행하고 선택하지 않았다면 다시 행동 3을 선택할 확률은 0.06(6%)가 된다. 이렇게 가장 보상 값이 높은 행동 5개에 대하여 확률을 적용해 본다. 만약 5개의 행동이 모두 선택되지 않았다면 보상 값이 –50보다 큰 임의의 행동을 선택하도록 하였다. 이는 여러 번 수행해 본 결과 부정적인 보상을 많이 받은 행동을 다시 수행하는 것을 방지해 준다.
| |
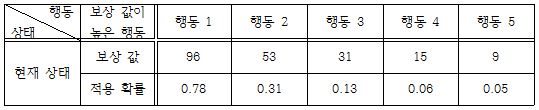 |
|
| ▲ 정렬된 보상 값에 따른 적용 확률 |
| |
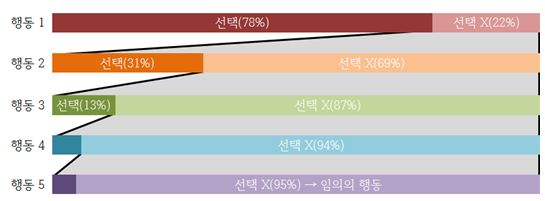 |
|
| ▲ 로봇이 수행할 행동을 결정하는 과정 |
이렇게 결정한 확률을 적용시킬 때에는 랜덤 함수를 이용하였다. ROBOTC에서는 rand함수가 –32768~32767 사이의 정수 값을 돌려준다. 이 rand함수에서 –32768과 0이 나오는 상황을 제거해 준 후 절댓값을 취해 1~32767까지의 값을 돌려주는 난수함수를 정의하였다. 그리고 난수함수에서 얻어낸 값과 난수함수에서 나타날 수 있는 최댓값인 32767에 적용시키고자 하는 확률을 곱한 값을 비교하여 난수함수에서 얻어낸 값이 더 작은 경우 행동을 선택하도록 하였다. 예를 들어 보상 값이 96이고 적용 확률이 0.78일 때는 난수함수를 통해 얻어낸 값이 32767 * 0.78 = 25653.3 보다 작을 경우 행동을 선택하였다.
| |
 |
|
| ▲ 확률을 적용시키는 원리 |
3. 보상 체계
보상 값에 변화를 줄 때에는 흰 영역과 검은 선을 구분하는 빛 센서 값의 경계를 설정하고, 빛 센서가 흰 영역 위에 놓여 있는 상황과 검은 선 위에 놓여 있는 상황만을 이용하였다. (2. 행동 선택) 과정에서 빛 센서 값을 측정하여 센서 값이 속해 있는 범위를 선택할 뿐 아니라 행동을 수행하기 전 각각의 빛 센서가 흰 영역 위에 놓여 있거나 검은 선 위에 놓여있는 상태를 파악한 후, 선택한 행동을 수행하고, 행동을 수행한 후의 빛 센서의 상태를 파악한다. 빛 센서의 상태는 아래 그림과 같이 4가지 상태가 존재할 수 있다. 아래 그림에서 원은 빛 센서의 상태를 나타낸 것으로, 흰색 원은 흰 영역 위에 놓여 있는 빛 센서의 상태를, 검은색 원은 검은 선 위에 놓여 있는 빛 센서의 상태를 의미한다.
| |
 |
|
| ▲ 빛 센서가 가질 수 있는 상태 |
행동하기 전의 상태와 행동한 후의 상태를 비교하여 보상 값을 변동시켜 주었다. 위 그림에서 B 상태에서 B’ 상태로 옮겨갈 수 없고, B 상태와 B’ 상태는 대칭이므로 두 상태를 같은 상태로 취급하여 보상 값을 변동시켜 주었다.
A 상태가 그대로 유지되는 경우는 두 빛 센서가 검은 선을 잘 따라가고 있는 상황이므로 보상 값을 증가시켜 주어야 한다. 반면에 A 상태에서 B 상태나 C 상태로 변화했다면 선을 이탈하는 방향으로 움직였으므로 보상 값을 감소시켜 주어야 한다. 필자는 A 상태가 그대로 유지되는 경우에는 보상 값을 10만큼 증가시켜 주었고, A 상태에서 B 상태나 C 상태로 변화한 경우에는 보상 값을 25만큼 감소시켜 주었다. 이러한 보상 값의 변동이 너무 크다면 학습 초기에 긍정적인 보상을 받은 행동만을 수행하거나, 대부분의 상황에서는 긍정적인 보상을 받을 수 있는 행동이었지만 특수한 상황이 발생하여 부정적인 보상을 받게 된 행동을 다음에 전혀 수행하지 않게 될 수 있다. 또한 보상 값의 변동이 너무 작다면 학습 시간이 오래 걸릴 수 있다. 또한 증가 값에 비해 감소 값이 너무 작으면 잘못된 학습을 할 수 있고, 증가 값에 비해 감소 값이 너무 크면 학습이 완료되지 않을 수 있다. 이러한 보상 값은 확률을 구하는 식, 학습의 주기, 모터의 최대 출력 등 다양한 요인에 의해 영향을 받기 때문에 필자는 다양하게 보상 값을 바꾸어 보며 실험적으로 보상 값을 설정하였다.
B 상태에서 A 상태로 변화하는 경우는 한쪽 센서가 흰 영역 위에 있었던 상황에서 검은 선을 잘 따라가고 있는 상황으로 변화한 것이므로 보상 값을 증가시켜 주어야 하고, B 상태에서 C 상태로 변화하는 경우는 검은 선에서 완전히 이탈한 것이므로 보상 값을 감소시켜 주어야 한다. 필자는 B 상태에서 A 상태로 변화하는 경우는 보상 값을 25만큼 증가시켜 주었고, B 상태에서 C 상태로 변화하는 경우에는 보상 값을 25만큼 감소시켜 주었다. A 상태를 그대로 유지하는 경우에는 보상 값을 10만큼 증가시켜 주었지만 B 상태에서 A 상태로 변화하는 경우에는 보상 값을 25만큼 증가시켜 주었다. 이는 A 상태를 그대로 유지하는 상황은 라인을 잘 따라가고 있는 경우 계속해서 발생하지만, B 상태에서 A 상태로 변화하는 경우는 한쪽 빛 센서가 검은 선을 이탈했다가 다시 검은 선 위로 돌아오는 순간에만 발생하기 때문이다. 즉, B 상태에서 A 상태로 변화하는 상황이 더 적게 발생하기 때문이다. 또한 B 상태를 그대로 유지하는 경우에는 보상 값을 변동시키지 않았는데, 이는 해당 상태가 그대로 유지되는 상황이 라인을 이탈하는 과정인지 라인으로 돌아오는 과정인지, 즉 긍정적인 보상을 주어야 하는지 부정적인 보상을 주어야 하는지 판단할 수 없기 때문이다.
C 상태에서 A 상태나 B 상태로 변화하는 상황은 검은 선을 완전히 이탈했다가 다시 라인으로 돌아오는 상황을 의미한다. 현재 해결하고자 하는 문제는 검은 선을 이탈하지 않고 잘 따라가는 것이므로 이러한 상황은 문제 해결에 도움을 주지 않는다. 따라서 이러한 상황에서는 보상 값을 변동시키지 않았다.
| |
 |
|
| ▲ 보상 체계 |
4. 소프트웨어 보완
모델링, 행동 선택, 보상 체계의 세 단계의 설계를 마치면 로봇은 학습을 할 수 있다. 학습 초기에는 라인을 계속해서 이탈하지만 시간이 지날수록 이탈 횟수가 점차 줄어들고 어느 순간 검은 선을 이탈하지 않고 원활하게 주행하는 모습을 볼 수 있다. 하지만 학습이 되는 과정에서 매우 불안정하게 주행하는 모습을 볼 수 있고, 로봇이 라인을 완전히 이탈할 때 마다 계속해서 로봇을 다시 검은 선 위로 올려주어야 하는 불편함이 발생한다.
주행의 불안정함은 관성에 의한 효과에 의해 발생하며, 잘못된 학습이 될 가능성이 있다. 예를 들면 오른쪽 센서는 흰 영역에, 왼쪽 센서는 검은 선 위에 있는 상황에서 로봇은 좌회전을 하도록 학습 되어야 한다. 하지만 급격한 우회전 이후에 좌회전을 시도한다면 관성에 의해 왼쪽 센서가 흰 영역으로 빠져나가는 상황이 발생할 수 있고, 급격한 우회전이 잘못된 행동이었지만 좌회전의 보상 값이 감소할 수 있다. 이러한 상황을 방지하기 위해 바로 직전 행동을 수행하기 전 빛 센서의 변환 값과 모터의 변환 값을 저장해 두고, 바로 직전 행동을 수행하기 전 빛 센서의 변환 값과 현재 행동을 수행하기 전 빛 센서의 변환 값이 같다면 이전에 하던 행동을 계속해서 수행하도록 하였다. 이를 통해 직선 구간에서 원활한 주행이 가능하게 되었고, 한쪽 빛 센서가 흰 영역으로 빠져나갔을 때 한 가지 행동을 유지하여 잘못된 학습을 할 가능성을 줄일 수 있었다.
로봇이 라인을 완전히 이탈할 때 마다 계속해서 로봇을 다시 검은 선 위로 올려주어야 하는 것은 불편할 뿐 아니라 자세를 바로 잡아주는 과정에서 잘못된 학습이 될 가능성 또한 존재한다. 이는 로봇이 라인을 완전히 이탈한 상황, 즉 두 빛 센서가 모두 흰 영역위에 있다고 인식되는 상황에서는 바로 직전에 수행한 행동을 반대로 하여 다시 라인으로 돌아갈 수 있도록 하였다. 단, 이러한 상황은 학습이 완료된 상황이 아니라 학습이 계속해서 이루어지고 있는 상황이기 때문에 이를 표현하기 위해서 라인으로 돌아갈 때는 소리를 발생시켰다. 이를 통해 로봇을 계속해서 검은 선 위로 올려주어야 하는 불편함과 그 과정에서 생길 수 있는 잘못된 학습의 가능성을 줄일 수 있었다.
블루투스 통신
한 대의 로봇으로 학습을 하는 것 보다 두 대의 로봇이 학습한 내용을 종합하면 학습 시간을 더욱 단축시킬 수 있을 것이라는 생각을 할 수 있었고, 블루투스 통신으로 이를 구현하였다. ROBOTC에서는 EV3간의 블루투스 통신을 지원하지 않아 NXT로 구현하였다. 두 로봇에서의 정보를 종합하여 학습한 경우와 그렇지 않은 경우를 비교하기 위해 데이터를 송신하는 로봇인 Sender 로봇과 데이터를 수신하는 로봇인 Receiver 로봇을 설정하였다. Sender 로봇은 Receiver 로봇으로 행동을 하기 전 센서의 변환 값, 선택한 행동(모터의 변환 값), 보상의 변화량의 세 가지 데이터를 송신하고 Receiver 로봇은 이를 수신하여 두 로봇의 학습 시간 차이를 확인할 수 있었다. 여러 차례 실험을 해 본 결과 Receiver 로봇이 Sender 로봇보다 더 빨리 학습을 할 확률이 높았으며, Sender 로봇이 더 빨리 학습된 경우에는 Receiver 로봇이 Sender 로봇의 정보를 통해 짧은 시간이 지난 후 Sender 로봇과 같은 모습으로 학습이 완료되는 것을 볼 수 있었다.
Q-Learning Line Tracer를 만들며
처음 Q-Learning Line Tracer을 구현하고자 했을 때는 다양한 자료를 조사하려고 하고, 다양한 동영상을 보며 그 원리를 파악하려고 했다. 계속해서 자료를 찾아보았지만 Q-Learning 알고리즘을 명쾌하게 이해할 수 없었다. 이러한 상태로 며칠을 보낸 후 계속 이렇게 있을 수는 없다는 생각에 과감하게 로봇을 만들기 시작했다. 시작은 조금 불안했지만 로봇을 만들어 가며 Q-Learning 알고리즘에 대해 더 잘 이해할 수 있게 되었고 결국 로봇을 완성시킬 수 있었다. 이 Q-Learning Line Tracer를 만들면서 가장 중요했던 것은 로봇의 구조와 소프트웨어 보다는 일단 부딪혀 보는 자세였다고 생각한다. 또한 이번 연구를 통해 로봇을 새로운 시각으로 바라볼 수 있었다. 마치 사람이 공부를 할 때에 요약 노트로 공부하거나 같이 협동하여 공부하면서 학습 시간을 줄이는 것처럼, 로봇도 학습해야 하는 범위를 줄이거나 두 대의 로봇이 서로 협동을 하며 학습 시간을 단축시키는 모습을 볼 수 있었고, 로봇의 모습이 인간과 비슷하다는 것을 느낄 수 있었다.
지금까지 인공지능 라인 트레이서를 구현하는 방법에 대해 자세히 소개하였다. on/off 제어 또는 PID 제어를 이용한 라인 트레이싱과 같이 현재 센서의 상태에 따라 수행할 행동을 인간이 직접 알려주는 것이 아니라, 실제 상황에서 정보를 수집하며 학습하여 로봇이 수행할 행동을 결정하는 방식을 구현하였다. 또한 이해를 돕기 위해 구현 도중에 필요한 지식들에 대해서도 설명하였다. 이 글을 통해 Q-Learning 알고리즘을 구현하는 데 어려움을 겪고 있는 분들께 도움이 되었으면 한다. 참고영상 : 수정 : https://www.youtube.com/watch?v=5TY3VjqjNhs ▒ 한조영 경기북과학고 2학년 |