| |
 |
|
| ▲ 김용덕 변리사 |
제조업 분야에서 사용되는 인공지능 하면 인공지능 로봇을 떠올리는 사람들이 많을 것 같다.
하지만, 제조업 분야에서 제조 설비의 고장 예측에 인공지능이 사용될 수 있다. 제조업에서 설비고장은 치명적이기 때문이다. 이에 많은 제조업을 수행하는 기업들이 AI 솔루션 기술을 도입하여 제조 설비의 고장을 예측하고 있다.
보통 고장 예측을 수행하기 위해서는 산업 설비에 설치된 센서로부터 획득된 데이터가 필요하다. 센서에서 획득된 데이터를 분석해서 장비의 고장을 예측할 수 있다. 이를 Anomaly detection(이상 탐지)이라고 한다.
Anomaly detection(이상 탐지)에 대해서 좀더 구체적으로 살펴보려고 한다. Anomaly Detection은 정상과 비정상(또는 이상치, 특이치)을 구별해내는 것을 의미한다. 제조업 분야에서는 제조 장비의 고장(이상)을 예측할 때 Anomaly detection을 사용한다. 즉, 제조 장비에 설치된 센서에서 센싱 된 데이터를 분석해서 고장을 예측할 수 있다. 뿐만 아니라, 의료 영상 분석 분야에서는 악성 종양을 검출하는데 Anomaly detection이 사용될 수 있다. 즉, 다양한 분야에 anomaly detection이 이용되고 있다.
Anomaly detection 모델을 학습시키는 방법은 다양하다. Supervised Learning(교사 학습), Semi-supervised Learning(반교사 학습), Unsupervised Learning(비교사 학습)과 같이 다양한 방법을 통해서 Anomaly detection 모델을 학습시킬 수 있다.
Supervised Learning(교사 학습)
생성 초기 단계의 인공지능 알고리즘은 신생아의 뇌와 같이 완전 백지상태라고 생각하면 된다(실제로 백지상태는 아니다). 따라서, 인공지능을 이용해서 어떠한 작업을 수행시키려면, 인공지능을 사람이 직접 가르쳐야 한다. 이렇게 인공지능을 가르치는 것이 교사 학습이다.
신생아에게 개와 고양이를 처음 보여주면, 신생아는 개와 고양이를 구분할 수 없다. 개와 고양이를 본 경험이 없기 때문이다. 즉, 어떻게 생긴 게 개이고 어떻게 생긴 게 고양이인지 모른다. 그럼, 신생아가 개와 고양이를 구분할 수 있도록 하려면 어떻게 해야 할까? 부모가 개를 보여주면서 "이건 개야.", 고양이를 보여주면서 "이건 고양이야." 이런 식으로 가르치게 된다. 이렇게 학습을 수차례 반복하다 보면, 신생아는 어느 순간부터 개와 고양이의 차이를 자기도 모르게 인지하게 된다. 그리고, 이런 학습 과정이 완료되면 신생아는 개를 볼 때 "개"라고 대답할 수 있게 되고, 고양이를 볼 때 "고양이"라고 대답할 수 있게 된다.
인공지능도 이와 마찬가지이다. 초기 상태의 인공지능은 어떤 이미지가 개 이미지이고 어떤 이미지가 고양이 이미지인지 구분할 수 없다. 인공지능이 학습을 받은 바가 없기 때문이다. 따라서, 인공 지능을 학습시키기 위해서는 사람이 직접 개가 포함된 이미지와 고양이가 포함된 이미지를 많이 준비해야 한다.
그리고, 사람이 직접 개가 포함된 이미지에는 '이 이미지는 개 이미지임'이라는 태그를 달고, 고양이가 포함된 이미지에는 '이 이미지는 고양이 이미지임'이라는 태그를 달아줘야 한다. 이렇게 태그가 달린 수많은 이미지를 인공지능에 입력을 하게 되면, 인공지능은 이미지와 태그를 같이 확인하면서 개 이미지는 어떠한 특성을 갖고 있고, 고양이 이미지는 어떠한 특성을 갖고 있는지를 자동으로 인식하게 된다.
이렇게 학습이 완료된 인공지능에 개 이미지가 입력되면, 학습할 때 사용했던 개 이미지랑 유사하다고 판단해서 개라는 출력값을 출력하게 되고, 고양이 이미지가 입력되면 학습할 때 사용했던 고양이 이미지랑 유사하다고 판단해서 고양이라는 출력값을 출력하게 된다.
그럼 Anomaly detection을 수행할 수 있도록 교사 학습을 수행하는 방법을 좀더 살펴보겠다.
학습용 데이터 셋이 있으면 모델 설계자는 정상과 관련된 데이터와 비정상과 관련된 데이터를 구분해서 학습용 데이터 셋에 라벨을 달아야 한다. 이를 라벨링이라고 한다. 일반적으로 교사 학습은 다른 학습 방법에 비해서 정확도가 높은 특징이 있다. 그래서 정확도가 요구되는 경우에는 교사 학습을 많이 이용된다. 하지만, Anomaly detection이 적용되는 일반적인 산업 현장에서는 정상 상태에서 측정되는 데이터의 양이 비정상 상태에서 측정되는 데이터의 양보다 많다. 즉, 정상으로 라벨링 된 데이터양이 너무 많게 되는 Class-Imbalance(불균형)의 문제가 발생하게 된다. 이렇게 Class-Imbalance의 문제가 발생하는 경우 Anomaly detection의 정확도는 떨어지게 된다. 즉, 균형 있게 데이터를 확보할 수 없기 때문에 교사 학습을 통해 모델을 학습시키는 것은 문제가 있다.
결과적으로, 학습용 데이터 셋에 대해 전처리를 수행하여 비정상과 관련된 데이터의 양을 증가시켜 Class-Imbalance 문제를 해결한 후 교사 학습을 수행하는 것이 좋다.
반교사 학습(Semi-supervised Learning)
교사 학습을 통한 Anomaly detection 모델을 학습시킬 때 가장 큰 문제는 비정상 상태와 관련된 데이터를 확보하기 어렵다는 것이다.
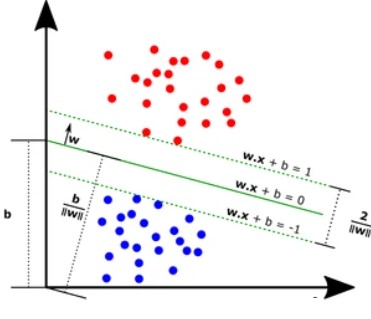
제조업의 경우 수백만의 정상 데이터를 취득하는 동안 단 한 번 비정상 데이터가 취득되는 상황이 종종 발생하기 때문이다. 이처럼 Class-Imbalance(불균형)가 심한 경우에 정상 상태와 관련된 데이터만 이용해서 모델을 학습시키는 One-Class Classification(또는 Semi-Supervised Learning)이 사용된다. 서포트 벡터 머신(SVM) 등을 이용하여 정상 상태와 관련된 데이터의 경계선을 결정하고, 결정된 경계선 밖의 데이터들은 전부 비정상으로 보는 학습 방법이다.
| |
 |
|
| ▲ Support Vector Machine |
이는 정확도가 다소 떨어질 수 있는 방법이긴 하지만, 불균형 데이터를 가지고 모델을 학습시킬 때 효과적이다.
비교사 학습(Unsupervised Learning)
반교사 학습에서 설명한 방식은 정상 데이터에 대한 라벨을 확보하는 과정이 필요하다. 비교사 학습은 획득된 데이터가 정상 데이터라고 가정하고 라벨 취득 없이 학습을 수행하는 방법이다. 대표적으로 오토인코더를 이용하는 경우 비교사 학습이 가능하다.
오토인코더(Autoencoder)
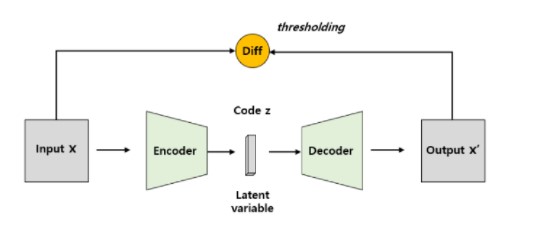
오토인코더는 입력된 데이터를 압축시키는 과정과 압축된 데이터를 복원시키는 과정을 수행하게 된다.
구체적으로, 오토인코더는 입력을 latent variable(Compressed feature)로 압축하는 인코더(Encoding DBN)와 latent variable을 원 데이터로 복원시키는 디코더(Decoding DBN)로 구성된다. 오토인코더를 이용하게 되면, 데이터 라벨링 없이 데이터의 주성분이 되는 정상 상태의 특징을 배우게 된다.
한편, 학습이 완료된 오토인코더에 정상 상태 데이터를 입력(Input)으로 넣어주게 되면 입력된 데이터와 동일한 데이터가 디코더에서 출력(Output)된다.
비정상 상태 데이터가 오토인코더에 입력으로 들어가면 오토인코더의 인코더와 디코더는 정상 상태 데이터로 학습이 되었기 때문에 제대로 압축 및 복원을 해내지 못한다. 따라서, 디코더에서 출력되는 최종 출력 데이터는 입력 데이터와 달라지게 된다.
결과적으로, 오토인코더에 입력된 입력 데이터(x)와 오토인코더에서 최종 출력된 출력 데이터(x')의 차이(Diff)가 얼마만큼 나는지를 확인해서 입력된 데이터가 정상 상태와 관련된 데이터인지 아니면 비정상 상태와 관련된 데이터인지 알 수 있게 된다.
| |
 |
|
| ▲ 출처: Improving unsupervised defect sementation by applying structural similarity to autoencoder, 2019, arXiv |
오토인코더를 활용한 특허
오토인코더를 이용해서 제조설비의 Anomaly detection을 수행하는 방법과 관련된 마키나락스의 특허를 하나 살펴보겠다.
정상 상태 데이터는 제조 레시피마다 다른 패턴을 갖게 된다. 따라서, 제조 레시피마다 다른 오토인코더를 학습시켜야 하는 것이 종래 기술이었다. 다만, 수많은 제조 레시피의 데이터들 각각을 이용해서 복수 개의 오토인코더를 학습시키면 시간적으로나 비용적으로 손해이다.
마키나락스는 이러한 문제를 해결하기 위해 오토인코더를 학습시킬 때, 제조 레시피에 대한 인자를 센싱 데이터와 함께 오토인코더에 입력하는 것을 제안했다.
구체적으로, 현재 어느 제조 레시피에서 센싱 된 센싱 데이터인지를 나타내는 feature 값(context indicator)을 센싱 데이터와 함께 오토인코더에 입력해 준다. 그리고, 오토인코더는 입력으로 들어간 센싱 데이터와 동일한 데이터가 디코더에서 출력되도록 학습된다.
이렇게 학습시키면 하나의 오토인코더로 다양한 제조 레시피 데이터의 정상과 비정상을 판별할 수 있게 된다.
구체적으로, 제조 레시피를 나타내는 값(Context Indicator)과 센싱 데이터(X)를 학습이 완료된 오토인코더의 입력으로 넣어주고, 출력된 값(X’)과 입력으로 사용했던 센싱 데이터(X) 사이의 차이 값을 산출한다. 만약 그 차이 값이 기 설정된 값 미만이면 정상으로 판별하고 그 차이 값이 기 설정된 값 이상이면 비정상으로 판별하게 된다.
보통 특허 출원을 위한 아이디어를 창출할 때 다음과 같은 방법을 많이 이용한다. 종래 기술(오토인코더)을 어느 특정 분야(제조업 분야)에 사용하는 경우 발생하는 문제점(제조 레시피마다 별개의 오토 인코더를 생성해야 하는 문제점)은 어떤 것이 있고, 이러한 문제점을 해결하기 위해 종래 기술(오토인코더)을 어떻게 변형하면 좋은지를 고민하는 방향(제조 레시피에 대한 정보를 같이 입력으로 넣어 줌)으로 아이디어 창출을 많이 한다. 그리고, 이런 방향으로 아이디어 창출을 한 후에 특허 출원을 하는 경우 특허 등록률이 상당히 높아지게 된다. |